Project - Visual PDF Compare Tool
I'm writing this separate article to describe the creation of a small utility (small demo here) for comparing two PDFs "pixel-by-pixel" to highlight differences. While I created this tool in the specific context of verifying documents within a publishing workflow, it could be useful for a wider range of use cases. Additionally, it had been a while since I worked with Unix utilities for image manipulation, so it was an interesting project.
The Concept
The original idea is fairly simple: make a PDF copy of an "original" manuscript and compare it with a PDF generated after applying some script-based modifications. The comparison needs to happen pixel by pixel due to the delicate nature of some changes and must provide:
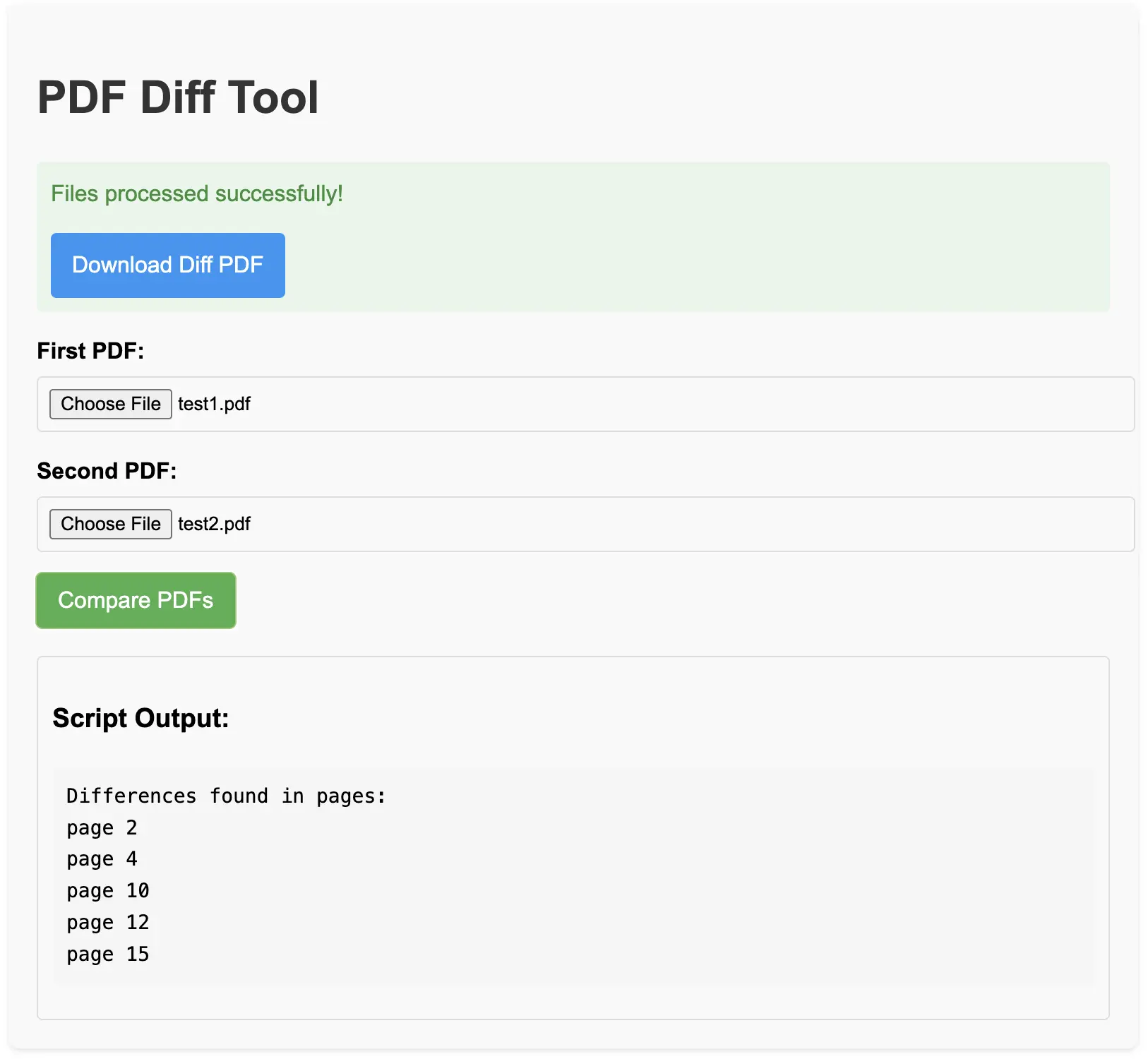
- A graphical output showing the differences visually between the two versions
- A text list of all differences found to allow examination of only the pages actually affected by changes
Instinctively, this seemed like a job for input/output, diff, and grep—in other words, time to write some bash.
In reality, it's not much bash code, just enough to string together a couple of programs and add some error handling to the script. The process is as follows:
- Convert the original color PDF to grayscale (for reasons beyond the scope of this article)
- Overlay the two PDFs "pixel by pixel"
- Create two outputs:
- A visual output where, in case of changes, the graphic elements before and after the change are overlaid with different colors to highlight exactly the shape of the discrepancy between the two versions
- A text output listing each page with its percentage of change, allowing quick extraction of page numbers where modifications occurred
Getting Started
First, you might already have all the necessary programs to reproduce what follows, so if you want to quickly try with two test PDFs, you can use these commands:
vim before.txt -c "hardcopy > before.ps | q"; ps2pdf before.ps before.pdf
vim after.txt -c "hardcopy > after.ps | q"; ps2pdf after.ps after.pdfNOTE: I found this one-liner directly in the Vim manual by searching for the word 'pdf'. This is a reminder from the universe, at least for me, that searching the manuals should always be the first thing to do. Evidently, someone already experienced using tools like pandoc or groff for simple PDF conversion and had the wise idea to add a dedicated note in the manual! Obviously, the aforementioned tools have their place, but in my opinion, they're particularly inconvenient for creating test documents or simple shared documents, especially when you don't need much control over the output.
The -c "..." syntax is equivalent to running :hardcopy > file.ps and then
:q but without opening Vim. See :help :hardcopy for more information. After taking a
look at the PS file contents if you wish, you can remove the .txt and .ps files.
The Core Script
Now that we have two PDFs, we can proceed to the heart of the script:
(cat $original_pdf | pdftoppm -gray - | convert - miff:- ;
cat $modified_pdf | pdftoppm -gray - | convert - miff:- ) |
convert - \( -clone 0-1 -compose darken -composite \) -channel RGB -combine $DIFFDIR/$page_number.jpgFirst, we use pdftoppm to convert the PDFs to Portable Graymap format. Converting PDFs to grayscale will help us more easily identify areas where colors change, even by a minimal percentage.
The second step uses convert, which is part of the famous ImageMagick command-line suite. While not installed by default, it's now used by many developers as a standard solution for image manipulation. We use convert to transform the PDF into the miff format, an intermediate ImageMagick format capable of preserving a large number of metadata (see https://imagemagick.org/script/miff.php).
NOTE: For an explanation of the miff:- syntax, see the convert manual just above the SEE ALSO section. This is a peculiar place to put such an explanation, which in my opinion should have been included at the end of the DESCRIPTION section, where the program's input and output are discussed.
The core of the visual overlap and diffing operation is performed by calling the convert command again. The composite option creates the overlap of images through the method specified by the -compose option, in this case, darken. Enclosing the two operations in a subprocess is useful because the clone option can easily read the two images to be overlapped from memory. The combine option will merge the two images so that the output consists of a single file per page.
The channel option is set to RGB to ensure that all the commands mentioned above act only on the Red, Blue, and Green channels, ignoring the Alpha channel. This works well in our case because the alpha channel adjustment is assumed to be handled upstream by the layout program. Applying transformations to the PDF's alpha channel would make it difficult to reason about how ImageMagick actually handles color differences. Instead, by using pdftoppm to transform the file to grayscale and using the RGB option, we don't have to worry about managing the fourth channel but can still highlight transparency differences in colors.
NOTE: ImageMagick has many options but also has an excellent guide (online, not the manual) with all options illustrated with examples.
Detecting Changes
The following snippet prints to stdout, for each page, the percentage of change found between the two PDF versions. It's very easy to grep for percentages different from 0 to get a list of pages affected by changes, or to highlight only pages that have a percentage greater than a certain value. I'll refer to the manual for the syntax of this part because it's too specific to be of general interest.
grayscale=$(convert $DIFFDIR/$page_number.jpg -colorspace HSL -channel g -separate +channel -format
"%[fx:mean]" info:)Conclusion
The interesting thing is how often we end up using tools belonging to the Unix philosophy, which is capable of creating not just "nice to have" programs but true "enablers", programs that are at the heart of a process and without which the process itself couldn't exist. In this case, without an adequate pdf output testing program, it would have been impossible to even think about automating the modification of book graphics.
As always, thank you for your time.
If you want to send me something, XY at gmail.com where X = tommaso and Y = bassignana, no dots between X and Y. I'm always interested in hearing different perspectives and I respond to every email ;)